
Let’s chat … bots
Given that chatbots and machine learning are among the hottest technologies in the world of startups, we figured it was a good opportunity to discuss our experience building Oli, Pounce, and friends. There are currently 10,000 bots (and counting) on Facebook to help you with everything from buying flowers to booking travel.
While it’s getting easier and easier to build a chatbot (you can probably find 100 blog posts testifying to that fact), it is still very hard to build a “good chatbot.” Before getting into the details, here’s a brief history of bots.
The birth of bots
Like Athena emerging directly from Zeus’ head, the first chatbot, named Eliza, was born from the mind of Joseph Weizenbaum in 1966. This bot and its earliest descendents were simple yet effective. They recognized specific language patterns and replied with evocative canned responses (e.g., a user might mention the word ‘MOTHER’ and the bot might reply with ‘TELL ME MORE ABOUT YOUR FAMILY’).
Thanks to the diligence of of early developers, these bots got pretty good given the constraints of technology at the time. Some people were even fooled into believing that they were chatting with an actual human — the mythical benchmark for passing the Turing Test.
However, this type of chatbot development hit a plateau pretty quickly, and developer enthusiasm petered out. Perhaps the most widely used bot in history, AIM’s Smarter Child, which reached more than 30 million people, was also of the pattern matching variety. Nonetheless, it was entertaining and attracted many millions of users trying to test its limits.
The reason for Smarter Child’s success, however, was not its utility (it had none) but the context of AOL Instant Messenger. By presenting itself in the context of the widely popular chat application of the early 2000s, it was very easy to try. Although its responses were canned, their cleverness was engaging enough to develop a “relationship” with millions of users around the world.
Why now?
So, if Bots have been around for 50 years, why are they now becoming popular again? No, it’s not because Computer Science has the same compulsion for remakes as Hollywood … but that’s not a bad answer.
Lately, there has been a series of technological developments that are coalescing to make this a pivotal time in the mass market proliferation of AI (and potentially a tipping point in human civilization, though that’s a story for another blog post). Here are the top three reasons why we’re seeing a resurgence of chatbots today:
Cheap parallel computation
The best description of this comes from Kevin Kelly’s new book The Inevitable (2016):
“Until recently, the typical computer processor could [process] only one thing at a time. That began to change more than a decade ago, when a new kind of chip, called a graphics processing unit, or GPU, was devised for intensely visual—and parallel—demands of video games, in which millions of pixels in an image had to recalculated many times a second. That required a specialized parallel computing chip, which was added as a supplement to the PC motherboard. … In 2009, Andrew Ng and a team at Stanford realized that GPU chips could run neural networks in parallel. … Traditional processors require several weeks to calculate all the cascading possibilities in a neural net with 100 million parameters. Ng found that a cluster of GPUs could accomplish the same thing in a day.”
Big Data
Every intelligence needs training. Even a human needs to be taught how to do a job. Andrew Ng explains the ramifications of Big Data like this: “AI is akin to building a rocket ship. You need a huge engine and a lot of fuel. The rocket engine is the learning algorithms but the fuel is the huge amounts of data we can feed to these algorithms.”
Better algorithms
The short list of open source tools for doing the sort of deep learning required to train an AI today are emerging as free and open software from companies like Google, Facebook, IBM, and other tech superpowers. These machine learning advancements make it so that non-technical users can easily train an AI without knowing anything about the extremely complex self-learning code powering this technology.
If you’re curious to do a deep dive into the world of machine learning, I suggest reading The Master Algorithm, which presents highly technical concepts in a relatively digestible way.
Building better bots
In the midst of wide-ranging enthusiasm for a chatbot renaissance, most developers fail to study the bots of yesteryear. As a result, many of today’s bots are buggy and frustrating. For instance, a conversation about the weather might go something like this:
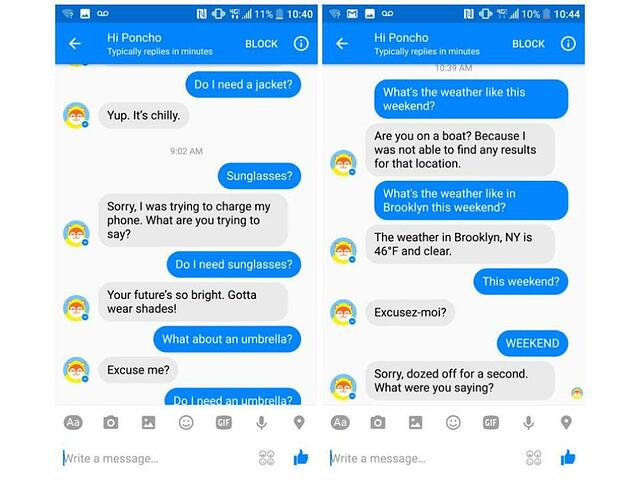
Hopefully failures like this don’t give all bots a bad name. To prevent more bot failures, here is a quick blueprint for how to make a bot with a better user experience:
- Clear instructions: Give the user examples (early and often) about how to properly talk to your bot!
- Going with the flow: If a user responds to a question with a question, the bot must be flexible enough to change the context of the conversation. Instead, most bots will continually reprompt the current question. This makes for a terrible experience that gets old fast.
- Eliminating excess: If you can eliminate words and messages, do it! Every message should be considered friction. Be ruthless with your bot and your users will thank you.
- Understanding slang: Users talk in slang (e.g. ‘brb’, ‘lol’, etc.). Your bot should understand (and even reply with) similar language.
- Vary stock responses: If your bot has a common go-to phrase in response to certain questions or commands, try to mix it up. The same message over and over and over makes Jack a dull boy!
- Remember what users say: The best bots have a memory. If a user tells your bot something, it should remember. LSTMs can be handy technology for this, too.
- Be vulnerable and honest about limitations: If your bot makes a mistake (and it will make many), it should apologize and own up to its flaws. Vulnerability paradoxically helps build trust and connection with bots … and people too.
- Supervise: Because bots are prone to error, you’ll have to set up a supervised machine learning process to catch errors and continue to train your bot. This should be done by a small group of experts. If you leave bot training to the Internet at large, you might have a disaster like Microsoft’s Tay.
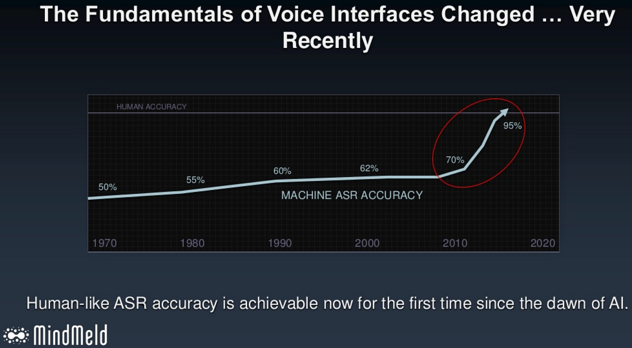
So, after taking all of this in (I know you enjoyed reading all of those technical articles), the only question remaining is … to bot or not to bot? What say you? If you’re still skeptical, I’ll leave you with a great image about the prospects for human-level accuracy in Automatic Speech Recognition (ASR) in the near future:
